

Pythonで
・S3からファイルを取得(ダウンロード)
できます!
この記事では
・プロファイルを指定した方法
紹介します!
※ローカルから実行します。Lambda関数からではなく。
前提
①外部ライブラリ「boto3」がインストールされていること。
pipコマンドでインストールする場合、以下でインストールできます
pip install boto3
②AWS CLIのプロファイルが設定済みであること。
コード
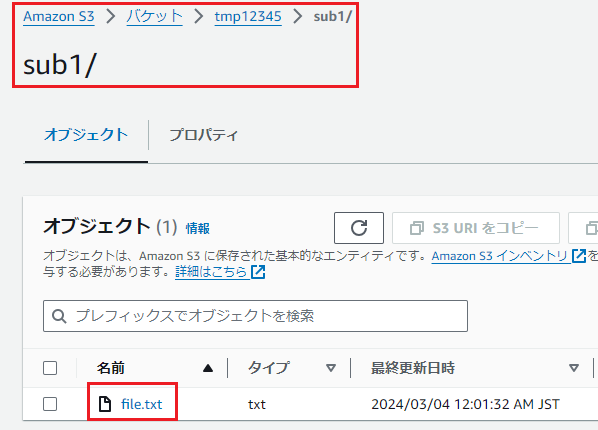
ここでは例として
・バケット「tmp12345」配下のフォルダ「sub1」配下にある
・ファイル「file001.txt」を取得(ダウンロード)
します。
from boto3.session import Session
from botocore.exceptions import ClientError
# プロファイル名
profile = "develop"
# バケット名
bucket = "tmp12345"
# フォルダ名とファイル名
key = "sub1/file.txt"
# 保存先となるローカルのファイルパス
filename = r"C:\Users\lunch\Desktop\file.txt"
try:
session = Session(profile_name=profile)
s3_client = session.client(service_name="s3")
# S3からファイルを取得(ダウンロード)
s3_client.download_file(Bucket=bucket, Key=key, Filename=filename)
print("S3からファイルを取得(ダウンロード)しました。")
except ClientError as e:
print("エラーが発生しました。")
print("エラーコード:" + e.response["Error"]["Code"])
print("エラーメッセージ:" + e.response["Error"]["Message"])
except Exception as e:
print("エラーが発生しました。")
print(e)
実行結果
S3からファイルを取得(ダウンロード)できました。


参考
上記のコードは以下の公式サイトを参考にして作成しました。
